
はじめに
「あの小説の、あの切ない空気感に近い作品をもっと読みたい」 「キーワード検索ではうまくヒットしない、抽象的な感覚で本を探したい」
読書好きなら一度は抱いたことのあるこの願いを、最新の自然言語処理技術(NLP)で解決するために開発したのが、「似てる小説さがすくん 」です。
本プロジェクトでは、青空文庫の文学作品を対象に、日本語BERTを用いたセマンティック検索(意味類似性検索)を実装しました 。また、開発にはClaude CodeなどのAIコーディング支援ツールをフル活用しています 。この記事では、システムの仕組みだけでなく、インフラ構築(Cloud Run)やハイライト機能の実装で直面した壁と、そこから得た学びについても共有します。
システム概要
「似てる小説さがすくん」は、単なる単語の一致ではなく、文章が持つ「意味」や「文脈」をベクトル化して比較するアプリケーションです。
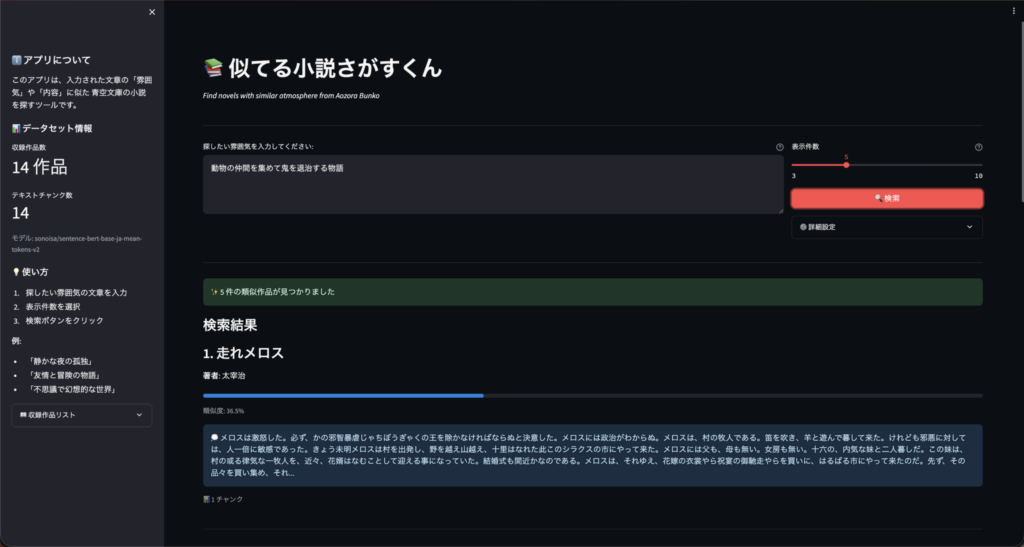
ユーザーが「静かな夜の孤独」といった抽象的なフレーズを入力すると、システムがそのニュアンスを理解し、夏目漱石や太宰治などの名作の中から最も関連性の高い作品や場面を特定して提示します。
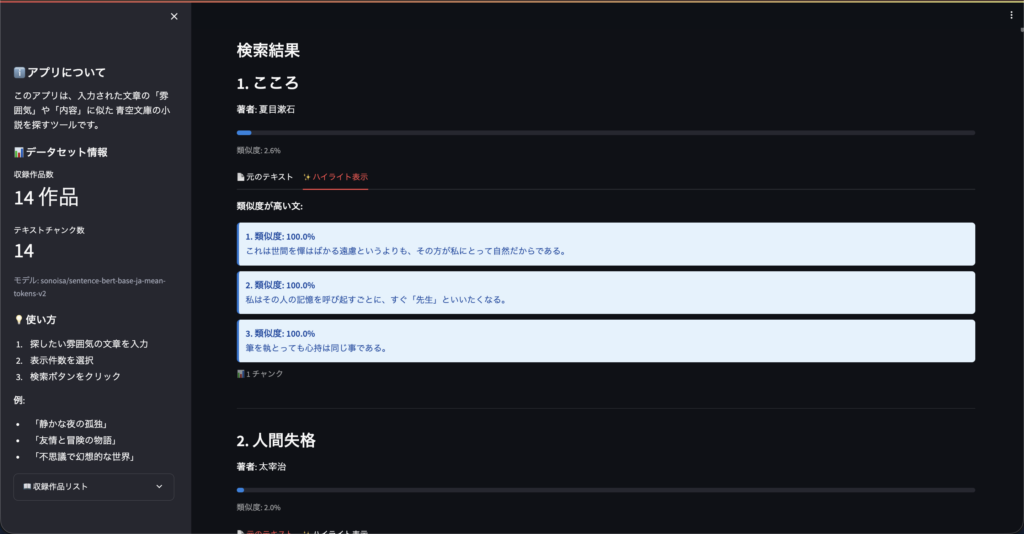
また、発展機能として「似てる箇所のハイライト表示」を実装し、小説のどの部分が入力した文章と似ているのかを視覚的に見ることができます。
ワークフローと技術スタック
言語:Python
言語モデル:Sentence-BERT(sonnoisa/sentece-bert-base-ja-mean-tokens-v2)
※Sentence-BERTとは、事前学習されたBERTモデル(Googleが発表した自然言語処理のモデルです。文の「文脈」を理解することに非常に長けています。)とSiamese Network(重みを共有した2つ以上の同一のネットワークを並列に構成する手法です。)を使い、高精度な文ベクトルを作る手法です。
ライブラリ: sentence-transformers, scikit-learn, numpy
フロントエンド:Streamlit
インフラ/CI・CD:Docker, Google Cloud Run, Cloud Build
実装のポイント
コサイン類似度による「意味」の比較
文章をベクトルに変換し、多次元空間上の「点」として扱います。比較している2つの文章が似ているかどうかは、ベクトルのなす角を利用した「コサイン類似度」で計算します。これにより文章の長さに左右されず、純粋な「意味の近さ」を1(とても近い)から-1(反対の意味)のスコアで判定することができます。
チャンク分割による精度向上
作品が長い小説もあるため、そのままではAIモデルの入力制限を超えてしまうことがあります。そこで、文章が途切れないように文章ごとのブロックの重複を持たせながらテキストを分割(チャンク化)し、解析を行っています。chunk_size: int = 800, # チャンクサイズ800文字
chunk_overlap: int = 100, # 100文字の重複
開発でぶつかった壁と得られた学び
壁1:Cloud Runへのデプロイと「ポート設定」の罠
Dockerを利用してCloud Runへデプロイしようとした際、Container failed to start... というエラーでタイムアウトを繰り返しました。
原因は2つありました。
- ポートの不一致:Streamlitはデフォルトで8501番ポートを使いますが、Cloud Runは8080番を要求します。DockerfileのCMDで --server.port=${PORT: -8080} と指定することで解決しました。
- タイムアウト問題:Cloud Runは起動時に数分以内に応答がないと強制終了します 。当初は起動時に重い解析処理を走らせていたため間に合いませんでした 。最終的に「Cloud Buildのビルド時に解析を済ませてしまう」設計に切り替えることで解決しました。
壁2:クラス設計とベクトルDBの初期化エラー
拡張機能としてQdrant(ベクトルDB)を組み込んだ際、AttributeError: 'EnhancedSearchEngine' object has no attribute 'vector_db' というエラーが発生しました 。 エラーログを辿ると、EnhancedSearchEngine クラスの初期化関数内で、必須であるQdrantのインスタンス化が漏れていたことが原因でした 。AIによるコーディング支援を受ける際も、全体のクラス設計を自分でしっかりと把握しておく重要性を痛感しました。
壁3:ハイライト表示実装における技術的な課題
「検索した文章と、小説のどこが似ているのか」を視覚的にわかりやすく可視化するハイライト機能の実装でも、壁にぶつかりました。
当初は、2つの文章を同時に比較してより高精度な抽出ができる「Cross-Encoder」というモデルの導入を目指していました。しかし、依存するライブラリやモデル間でバージョンの不一致が多発し、どうしてもエラーを解決しきれなかったため、このアプローチは断念することになりました。
そこで方針を切り替え、「既存の技術を組み合わせて泥臭く解決する」というアプローチに変更しました。具体的には、以下の3ステップでハイライトを実現しています。
- 分解する(チャンクの細分化) ヒットした小説の長いテキストブロックを、句点(。)などを基準にして「1文ずつ」バラバラに分割します。
- 総当たりで計算する バラバラにした「文の数」だけ、
scikit-learn(コサイン類似度)を何度も呼び出して、ユーザーの検索クエリとの類似度スコアを1つずつ計算させます。- クエリ vs 文1 → スコア 0.2
- クエリ vs 文2 → スコア 0.9(似ている!)
- クエリ vs 文3 → スコア 0.3
- アプリ側で色付けする 計算結果のスコアをチェックし、「しきい値を超えた(=似ていると判定された)文」に対して、アプリ側でHTMLタグ(
<mark>や<span>など)を差し込み、色を付けて画面に表示します。
AIコーディング支援ツール(Claude Code)を使って得た知見
- プロンプトの「丸投げ」はえらいことになる
当初は、「作りたい機能の要件をしっかり調べてプロンプトを作り、そのままClaudeに投げれば一気に作ってくれるだろう」と考えていました。しかし、これをやるとコードがカオスな状態になり、かえって収集がつかなくなりました。 - 「1関数ずつ」のマイクロステップが最適解
一気に作らせるのではなく、「1個の関数を作成させて、動作を確認し、問題なければ次へ進む」という進め方が、結果的に最も早く確実な方法だと気づきました。AIへの指示もアジャイルに行う必要があると気づきました。 - 「Planモード」による事前すり合わせの強力さ
Claude Codeの機能の中で特に有用だったのが「Plan mode」です。いきなりコードを書かせるのではなく、まずは「どう実装するか」についてClaudeと会話して方針(Plan)を固めます。その方針に納得してから実装フェーズに移ってもらうことで、AIの勘違いによる間違いや手戻りを劇的に減らすことができました。
終わりに
似てる小説さがすくん」の開発を通じて、自然言語処理の実装からインフラ構築まで、非常に多くの学びを得ることができました。特に「エラーログの正しい見方」や「実装方針を柔軟に切り替える判断力」は、今後の開発における大きな武器になると感じています 。今後は、メタデータフィルタリングを活用した「ジャンル・作者による絞り込み機能」の追加や 、さらなるデータセットの拡充に挑戦していきたいと考えています。また、ローカルエンベディングモデルを活用したプロダクト開発も続けたいです。